As a data scientist, your work life will focus on value from data. Working on data and deriving valuable
information from this asset will always be your top priority. You only do not want to explore the data, but
you also want the uncovered hidden patterns and trends in the data to be used for decision making.
With the new problem being more data and less information, it is critical to have a strategy in place
regarding how to make the information extracted from data available to end users. That is, you want
the information derived from the data to be actioned and used by relevant stakeholders.
Otherwise, the effort used in exploring the data, building models and making predictions may not
realise the intended business benefits. This sounds counter-intuitive but it is the reality of many data
scientists with just PowerPoint presentations the only thing from their work or a report of their findings.
You can change this with more accessible and easy to deploy technologies at a reduced cost and time.
After spending a lot of time preparing your data, training the models and making predictions, you need
to put all these into a pipeline so that the model can be used in applications and other downstream
processes. Also, you might want to display the results in a dashboard for end users.
You can change this with more accessible and easy to deploy technologies at a reduced cost and time.
After spending a lot of time preparing your data, training the models and making predictions, you need
to put all these into a pipeline so that the model can be used in applications and other downstream
processes. Also, you might want to display the results in a dashboard for end users.
Automating the E2E process also enables the pipeline to automatically ingest new data as they come in
and include them as part of the dataset to pick up new trends and patterns in the data for more accurate
predictions.
and include them as part of the dataset to pick up new trends and patterns in the data for more accurate
predictions.
There are a few options in the market. You could use AWS, Google Cloud or Microsoft Azure. In this
blog, I will be writing about Microsoft Azure. There are numerous advantages of using cloud computing,
these include flexibility, automated software updates, limited capital outlay, version control, collaboration
and remote working.
these include flexibility, automated software updates, limited capital outlay, version control, collaboration
and remote working.
Before we look at model operationalisation, I will like to state the main steps involved in a typical data
science project after business understanding, ingesting relevant datasets and data exploratory analysis
stage. These are Data Preparation, Data Transformation, Model Training and Model Testing.
science project after business understanding, ingesting relevant datasets and data exploratory analysis
stage. These are Data Preparation, Data Transformation, Model Training and Model Testing.
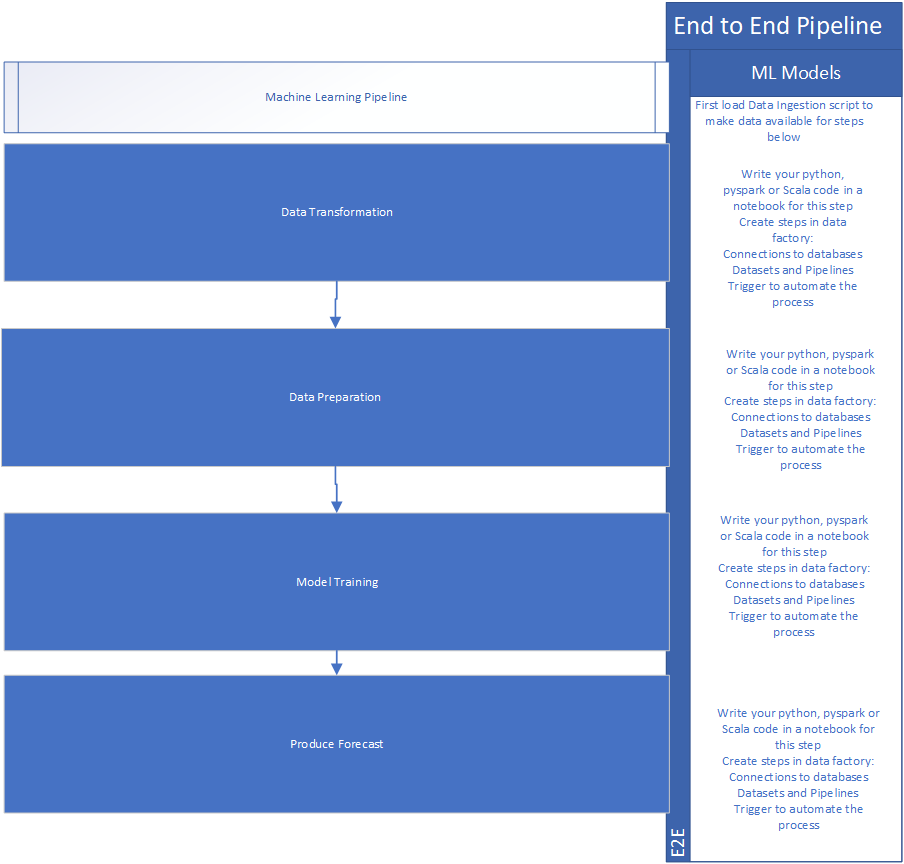
Note: This is just an example and will be different for every project, some project will require more or less
data aggregation of the dataset used.
Each of the data science processes will be part of the steps highlighted below using products available in
Azure subscription:
Azure subscription:
Step One:
Set up an Azure subscription to have access to all the resources required. There are a few options here
which include setting up a Data Science Virtual Machine or creating a Databricks workspace, if you have
a big dataset. Use the notebook to write all your code for the data science work, such as Azuredatabricks,
it runs on Spark to use parallelisation and distribution dataframe structure to reduce compute time and
significantly reduces the execution time. This is very important especially for big datasets and IoT data.
An alternative to this is to use built-in Azure Machine Learning models that comes with your Azure
subscription. However, this is not bespoke and might have less flexibility.
which include setting up a Data Science Virtual Machine or creating a Databricks workspace, if you have
a big dataset. Use the notebook to write all your code for the data science work, such as Azuredatabricks,
it runs on Spark to use parallelisation and distribution dataframe structure to reduce compute time and
significantly reduces the execution time. This is very important especially for big datasets and IoT data.
An alternative to this is to use built-in Azure Machine Learning models that comes with your Azure
subscription. However, this is not bespoke and might have less flexibility.
Step Two:
Productionise your machine learning models using Azure Data Factory. This will take care of data
ingestion, preparation and transformation using scripts written in either Python or Scala in Azure
Databricks.
Step Three:
Application Insights is used to monitor the performance of your pipeline through configure telemetry as it
reports all exemptions and events happening across the pipeline. Continuous Integration/Continuous
Delivery (CI/CD) can be activated on Azure DevOps- Using CI/CD capability in DevOps for automated
integration of new features in your code from git. New features will be added automatically to your models
using this CI/CD framework.
reports all exemptions and events happening across the pipeline. Continuous Integration/Continuous
Delivery (CI/CD) can be activated on Azure DevOps- Using CI/CD capability in DevOps for automated
integration of new features in your code from git. New features will be added automatically to your models
using this CI/CD framework.
To summarise, following these steps will enable you to operationalise your models quickly, efficiently
and scale up the solution easily. Scaling up will be easy due to the ability to configure your cluster
to scale up or down automatically depending on the required computing requirement.
Technology is always changing and data science is an iterative process, so an agile mindset and
methodology are important for continuous improvement of your applications or solution. Lastly, you
can generate REST API in Azure API Management to share your predictions with other users.
Mohegan Sun Pocono - Mapyro
ReplyDeleteThe 경주 출장마사지 Mohegan Sun Pocono in Wilkes-Barre, Pennsylvania 남원 출장마사지 is an 8,000 foot (15,000 m2) 여주 출장안마 casino and hotel, 목포 출장샵 offering 1,800 slots, 70 table games and a variety of live entertainment Location: 1280 Highway 315Phone: 1-800-589-7711 경상북도 출장샵